本地部署并使用DeepSeek量化版本
本地部署大模型一般有以下几种方式:
| 方式 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| Ollama | 推理速度快,计算资源消耗低 | 模型精度有所损失 | 适用于对精度要求不高的场景 |
| LM Studio | 推理速度快,计算资源消耗低,支持图形化交互 | 模型精度有所损失 | 适用于对精度要求不高的场景 |
| vLLM | 推理速度快,计算资源消耗低,支持分布式部署 | 模型精度有所损失,部署复杂度高 | 适用于对精度要求不高的场景 |
下面使用Ollama和Open WebUI来实现DeepSeek-R1的本地部署及使用
DeepSeek介绍
DeepSeek是一个基于LLM的对话模型,由DeepSeek团队开发,旨在为用户提供高效、准确的对话体验。
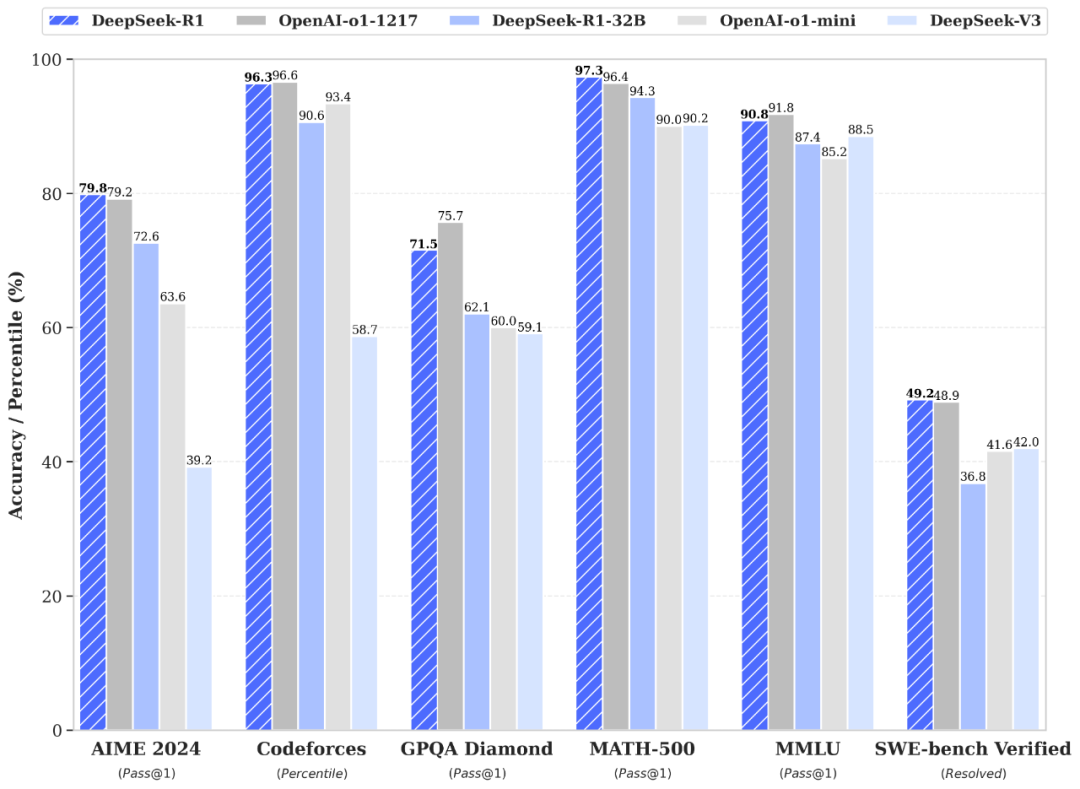
DeepSeek-V3 在推理速度上相较历史模型有了大幅提升。在目前大模型主流榜单中,DeepSeek-V3 在开源模型中位列榜首,与世界上最先进的闭源模型不分伯仲。
DeepSeek-R1 在后训练阶段大规模使用了强化学习技术,在仅有极少标注数据的情况下,极大提升了模型推理能力。在数学、代码、自然语言推理等任务上,性能比肩 OpenAI o1 正式版。
Ollama介绍
Ollama 是一个专注于本地化部署和运行大型语言模型(LLM)的工具,旨在让用户能够在自己的设备上高效地运行和微调模型。
官方首页简单介绍了 Ollama 能在本地运行的模型,包括 Llama 3.3, DeepSeek-R1, Phi-4, Mistral, Gemma 2 等。
Open WebUI介绍
Open WebUI 是一个可扩展、功能丰富且用户友好的自托管 AI 平台,旨在完全离线运行。它支持各种LLM运行器,如 Ollama 和 OpenAI 兼容的 API,并内置了 RAG 推理引擎,使其成为强大的 AI 部署解决方案。
本地部署DeepSeek-R1
接下来将使用Ollama和Open WebUI来实现DeepSeek-R1的本地部署及使用。
安装Ollama
安装Ollama比较简单,直接在ollama download页面下载对应系统的版本安装包即可。
MacOS安装
下载完Mac版安装包之后,直接解压后放入应用程序中即可,初次运行应用的时候,有使用提示。
命令行查看Ollama版本
$ ollama --version
ollama version is 0.5.7安装DeepSeek-R1
安装完Ollama之后,就可以直接使用ollama run ***在命令行来运行模型了,如果本地没有对应的模型,会自动下载,(这个下载肯呢个会比较慢)。
我们在Ollama Models中选择一个合适的DeepSeek-R1的量化版本,这里我们先选择的1.5b的模型。
$ ollama run deepseek-r1:1.5b
pulling manifest
pulling manifest
pulling manifest
pulling manifest
pulling manifest
pulling manifest
pulling manifest
pulling manifest
pulling manifest
pulling aabd4debf0c8... 100% ▕█████████████████████████████████████████████████████████████████████████████████████████▏ 1.1 GB
pulling 369ca498f347... 100% ▕█████████████████████████████████████████████████████████████████████████████████████████▏ 387 B
pulling 6e4c38e1172f... 100% ▕█████████████████████████████████████████████████████████████████████████████████████████▏ 1.1 KB
pulling f4d24e9138dd... 100% ▕█████████████████████████████████████████████████████████████████████████████████████████▏ 148 B
pulling a85fe2a2e58e... 100% ▕█████████████████████████████████████████████████████████████████████████████████████████▏ 487 B
verifying sha256 digest
writing manifest
success由于本地还没有deepseek-r1:1.5b模型,所以需要下载模型,下载完成之后,命令行就直接进入到了Ollama的交互界面。我们可以直接问问题了。 我们来测试一下一个经典的比较大小的问题。
>>> 5.13和5.2那一个数大?
<think>
首先,比较两个数的整数部分。两者都是5。
接下来,比较小数部分。0.13小于0.2。
因此,5.13比5.2小。
</think>
要比较 **5.13** 和 **5.2** 的大小,可以按照以下步骤进行:
1. **比较整数部分**:
- 两者都是 **5**,相等。
2. **比较小数部分**:
- 小数部分为 **0.13** 和 **0.2**。
将 **0.2** 转换为三位小数,得到 **0.20**。这样,**0.13 < 0.20**。
因此,**5.13** 比 **5.2** 小。
最终答案是:
\[
\boxed{5.13 \text{ 小于 } 5.2}
\]退出交互式命令行,可以使用 Ctrl+d和/bye。
Use Ctrl + d or /bye to exit.
>>> /bye至此我们就已经在本地通过Ollama下载并运行了DeepSeek-R1的1.5b量化版模型了。命令行交互还不是很友好,那么下面我就使用Open WebUI来和Ollama运行的本地模型交互,并且可以更方便的进行模型管理。
安装Open WebUI
这里我们选择在Docker中安装Open WebUI。
下载Open WebUI镜像
先搜索Open WebUI镜像,找到需要安装的镜像。
$ docker search open-webui
NAME DESCRIPTION STARS OFFICIAL
backplane/open-webui Automated (unofficial) Docker Hub mirror of … 6
dyrnq/open-webui ghcr.io/open-webui/open-webui 38
xuyangbo/open-webui open webui, a front end for LLM. https://git… 1
imroc/open-webui 0
qiruizheng/open-webui 0
0nemor3/open-webui 0
justmbert/open-webui 0
mbentley/open-webui 0
ag471782517/open-webui 0
saif233/open-webui 0
t9kpublic/open-webui 0
joeymartin77/open-webui 0
lukasthirdmind/open-webui 0
charnkanit/open-webui 0
wind520/open-webui ghcr.io/open-webui/open-webui 0
yoprogramo/open-webui open-webui compiled image 0
mars1128/open-webui 0
sfun/open-webui 0
nirmaaan/open-webui Deployment of Open WebUI on Azure 0
tribehealth/open-webui 0
dimaskiddo/open-webui Debian Based Open-WebUI Image Repository 0
openwrtclub/open-webui 0
girishoblv/open-webui 0
bean980310/open-webui 0
whatwewant/open-webui这里我们选择官方的dyrnq/open-webui镜像。
下载dyrnq/open-webui镜像
$ docker pull dyrnq/open-webui
Using default tag: latest
latest: Pulling from dyrnq/open-webui
4d2547c08499: Pull complete
93aa4e5d5dd6: Pull complete
1af95936e70e: Pull complete
030ad528ba70: Pull complete
ffca15c0b2b5: Pull complete
4f4fb700ef54: Pull complete
8e313df310c8: Pull complete
7aeddd66d1eb: Pull complete
a4d671c59575: Pull complete
79973909b43a: Pull complete
a9bbb08adf77: Pull complete
7298ee4f053d: Pull complete
d2f87ad13d61: Pull complete
d1fe9fe53d79: Pull complete
5577287d6500: Pull complete
Digest: sha256:fbe4e8219e0598d05a6c67340b573a9bbb7d6de493baecc5d8d1f2d75b43f206
Status: Downloaded newer image for dyrnq/open-webui:latest
docker.io/dyrnq/open-webui:latest
What's next:
View a summary of image vulnerabilities and recommendations → docker scout quickview dyrnq/open-webui提示 也可以选择docker pull ghcr.io/open-webui/open-webui:main命令来拉取镜像。
提示 由于国内的镜像源现在好多都不行了,可以使用的代理
运行open-webui容器
通过openwebui 文档我们可以知道,在运行Ollama的机器上,我们可以直接使用docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main来启动容器。但是这里有一点儿区别,我们使用的是docker pull dyrnq/open-webui拉取的镜像,所以这里需要将镜像名称更新为dyrnq/open-webui:latest。如果按 Open WebUI 文档使用docker pull ghcr.io/open-webui/open-webui:main拉取的镜像,就不需要改变。
$ docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always dyrnq/open-webui:latest
4d323fdaef6b446abc10d14f6677e5da2fc4a83b5828d42e18c8e6c45982e65c启动容器后,本地访问http://localhost:3000,可以看到登录页面。点击之后就会让你先创建管理员账号(第一次访问的时候)。创建成功后就可以使用了。
目前在在M1 + 16GB 的 MacBook Pro 上运行了DeepSeek-R1-Distill-Qwen-7B、deepseek-r1:1.5b、Qwen2.5-3B-Instruct三个模型,DeepSeek-R1-Distill-Qwen-7B的输出情况是7~10 token/s,deepseek-r1:1.5b的输出情况是20~30 token/s,Qwen2.5-3B-Instruct的输出情况是~20 token/s。
Open WebUI中下载切换模型
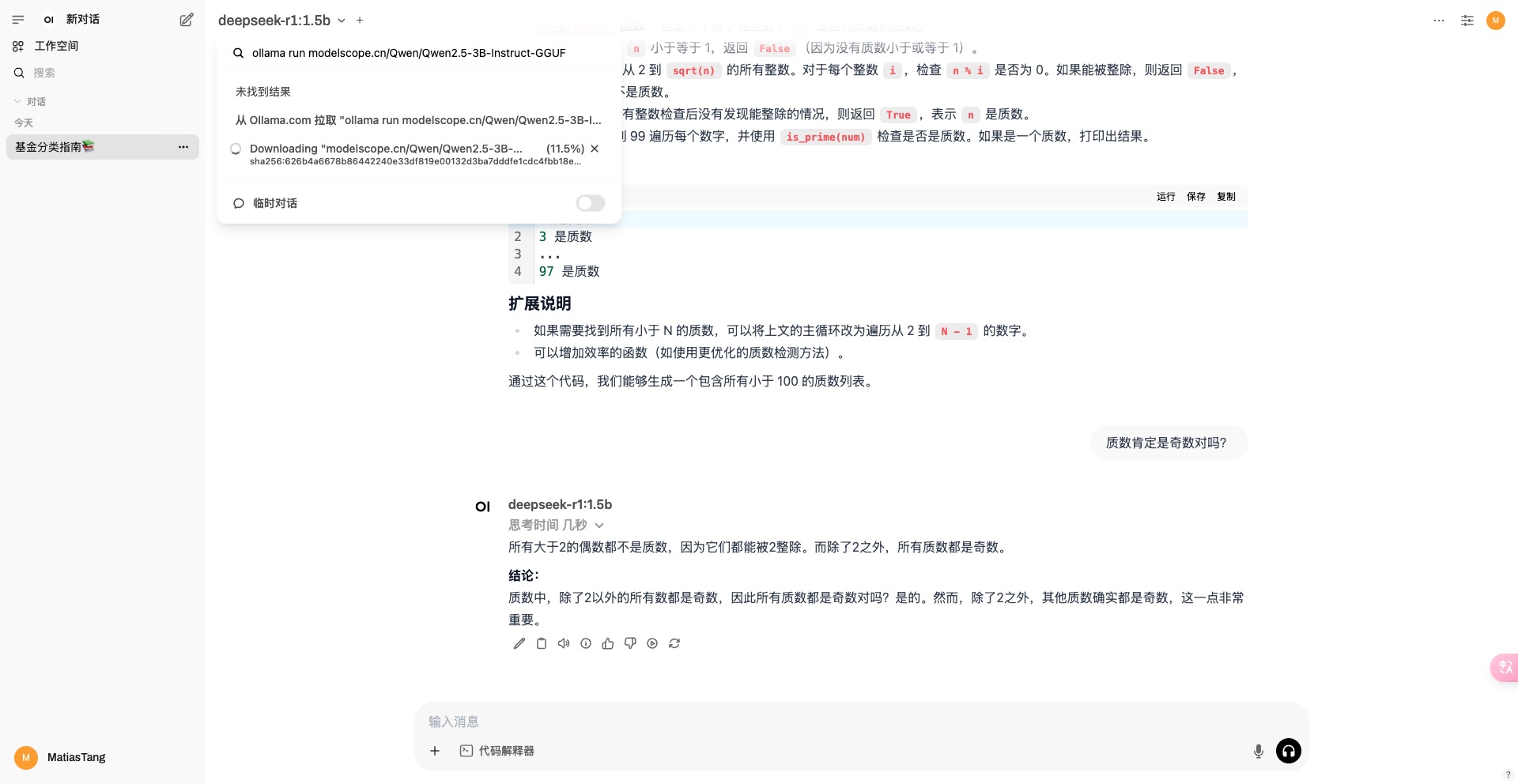
在页面的右上角可以切换不同的模型,切换了之后,再问问题就是使用的对应的模型了。如果本地没有想要的模型,我们也不用去命令行下载了,直接在搜索框中输入ollama run ****后,就可以在下拉框看到,从ollama提取模型 的提示,点击之后就开始拉取模型了。
模型下载
上面提到过,我们使用Ollama run ***会自动下载模型,也可以在Open WebUI的交互界面中下载模型。但在国内下载模型比较慢,所以建议优先使用ModelScope中的模型。
得易于ModelScope社区上托管了数千个优质的GGUF格式的大模型(包括LLM和视觉多模态模型),并支持了Ollama框架和ModelScope平台的链接,通过简单的 ollama run命令,就能直接加载运行ModelScope模型库上的GGUF模型。
如此我们只需要修改一下命令即可,例如ollama run modelscope.cn/Qwen/Qwen2.5-3B-Instruct-GGUF拉取Qwen2.5的模型。默认是Q4_K_M版本。
Ollama加载ModelScope模型需要使用GGUF格式的模型,具体查看Ollama加载ModelScope模型。如果下载其他模型,我们直接在ModelScope Models中搜索即可。如搜索Deepseek GGUF就能找到DeepSeek的GGUF格式的模型文件。选择具体的模型之后,点击进入详情,在模型的名称下面,就是路径,点击复制,修改命令即可。
如果在ModelScope中没有找到对应版本的模型,我们可以选择:
- 使用代理下载模型
- 手动下载模型到本地(可以选择在
huggingface),并在Open WebUI中导入。 - 转换模型文件格式为
GGUF格式。我们可以选择并上传到ModelScope中。
模型选择
Ollama提示我们应该至少有 8 GB 的 RAM 来运行 7B 型号,16 GB 的 RAM 来运行 13B 的型号,32 GB 的 RAM 来运行 33B 型号。
DeepSeek-R1各量化版本对显存或内存的预估如下:
1.5b大小的模型通常需要8GB RAM,针对边缘设备上的快速推理进行优化的轻量级版本。7b大小的模型通常需要16GB RAM,适用于通用推理任务的平衡模型。8b大小的模型通常需要32GB RAM,有更高的准确性和更好的上下文理解。14b大小的模型通常需要64GB RAM,推理和解决问题的能力得到提高。32b大小的模型通常需要128GB RAM,更强的逻辑分析和更精细的逐步输出。70b大小的模型通常需要256GB RAM,适用于高级人工智能驱动应用程序的高端版本。671b大小的模型通常需要512GB RAM,专家混合 (MoE) 模型,每个令牌激活 370 亿个参数,以实现最先进的推理性能。
本地运行DeepSeek-R1 671B的量化版本
Ollama 上唯一真正的 DeepSeek-R1 模型是 671B 版本,网址为 https://ollama.com/library/deepseek-r1:671b。其他版本是蒸馏模型。
如何使用与 Open WebUI 集成的 Llama.cpp 运行完整的 DeepSeek-R1 动态 1.58 位量化模型,具体查看Run DeepSeek R1 Dynamic 1.58-bit with Llama.cpp
DeepSeek-R1动态量化版本,查看deepseekr1-dynamic
